Linux的文件系统(4)——块、索引、链接与文件类型
本文源自 阮一峰的网络日志:理解inode,略作修改
Linux 以文件的形式对计算机中的数据和硬件资源进行管理,也就是彻底的 一切皆文件
反映在 Linux 的文件类型上就是:普通文件、目录文件、设备文件、链接文件、管道文件、套接字文件等等。而这些种类繁多的文件又被 Linux 使用目录树进行管理,就是以根目录(/)为主,向下呈现分支状的一种文件结构
Sector、Block与Inode
文件存在硬盘上,硬盘的最小存储单位叫做 sector(扇区,常见512B),多个 sector 组成一个 block(块,常见4096B,即连续8个sector组成一个block)
操作系统一次性读取一个block(即8个连续扇区),以提高磁盘IO效率。也就是说,block是磁盘读写的最小单位
所有的文件都由多个 block 组成。显然,还需要一个结构存储文件元信息(文件的创建者、创建日期、内容大小等),这就是 inode(索引节点,index node)
inode(索引节点)用于索引一个文件的所有block(块)。inode维护文件的元信息,可以用 stat <path> 命令来查看
$ stat ./test.py
File:"test.py"
Size:3217 Blocks:8 IO Blocks:4096 普通文件
Device:fd01h/64769d Inode:529253 Links:1
Access:(0644/-rw-r--r--) Uid:( 1000/ username) Gid:( 1000/ username)
Access:2022-02-07 21:52:22.794652238 +0800
Modify:2022-02-07 21:52:22.773652074 +0800
Change:2022-02-07 21:52:22.777652105 +0800
除了 文件名 以外所有的信息,都在inode中
Inode的大小与Inode数量上限
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域:一个是数据区(data area),存放block;另一个是inode区(也叫inode表,inode table),存放inode。实际上还有其他区,暂时不考虑
每个inode节点的大小,一般是128B或256B。可以用类似 dumpe2fs -h <disk_path> 命令查看
$ dumpe2fs -h /dev/sda1 | grep "Inode size"
dumpe2fs 1.41.12 (17-May-2010)
Inode size: 128
/dev/sda1指挂载的SATA盘,暂且不表
inode节点的最大数量,在格式化时就给定。在初始化文件系统时,inode table初始大小为0,然后,操作系统每分配1024B或2048B给data area,就分配inode大小的空间(128B或256B)给inode table,保持2048 : 256 = 8 : 1的分配比例。注意,此处仅仅是保持data area与inode table的分配比例(如8:1),与未来一个inode指向多少block无关
假定在一块2GB的硬盘中,data area与inode table的分配比例为8 : 1,则inode table占用11.11%的磁盘空间,即227.56MB;inode size 256B,则inode数量的上限为932067。
使用如下 df -i 命令查看每个硬盘分区的inode数量上限、已用数量、剩余数量等
$ df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
/dev/vda1 2621440 88600 2532840 4% /
devtmpfs 124248 328 123920 1% /dev
tmpfs 126863 2 126861 1% /dev/shm
tmpfs 126863 412 126451 1% /run
tmpfs 126863 16 126847 1% /sys/fs/cgroup
tmpfs 126863 1 126862 1% /run/user/1000
既然inode节点的数量存在上限,而每个文件又必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况(如每个文件的大小都小于2048B)。这时,就无法在硬盘上创建新文件了
Inode号
Linux系统使用inode号来识别文件,文件名仅仅是文件的别名
表面上,用户通过文件名打开文件——实际上,系统内部分三步完成这一过程:
- 找到文件名对应的inode号(内存)
- 通过inode号码,获取inode内容(磁盘)
- 最后,根据inode内容,找到文件数据存储的所有block,读出数据(磁盘)
使用 ls -i <path> 命令查看文件名对应的inode号码
$ ls -i ./test.py
529253 ./test.py
由于inode号码与文件名分离,这种机制也导致了一些Unix/Linux系统特有的现象:
- 有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用
- 移动文件或重命名文件,只是改变文件名,不影响inode号码
- 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名
这些特点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收
文件与目录
普通文件
从Linux的角度来说,类似mp4、pdf、html这样应用层面上的文件类型都属于普通文件,Linux用户可以根据访问权限对普通文件进行查看、更改和删除。我们知道,文件的属性,权限,大小,占用哪些数据块是存在inode当中的
这里注意一点:inode 当中并没有存放文件名,这是因为文件名存放再目录文件中
目录文件
目录文件的内容是该目录文件下文件名和其inode编号的一个映射关系
最简单的保存格式就是 列表,就是一项一项地将目录下的文件信息(如文件名、文件 inode、文件类型等)列在表里。但是如果一个目录有超级多的文件,我们要想在这个目录下找文件,按照列表一项一项地找,效率就不高了,这时可以用 哈希表
Linux系统的ext文件系统就是采用了哈希表,这种方法的优点是查找非常迅速,插入和删除也比较简单(不过需要一些预备措施来避免哈希冲突)
ls <path> 命令可以列出目录文件中的所有文件名
$ ls ./test/
admin.py test.py test.log
使用 ls -i <path> 命令则可以列出整个目录文件,即文件名和inode号码
$ ls -i ./test/
527836 admin.py 527838 test.py 527807 test.log
相比ls -i <file> 只需要查询文件名到inode的map,ls -i <dir> 需要则多一次读取目录文件的开销
更详细的信息则需要进一步根据inode号码读取inode的信息,如 ls -al <path>
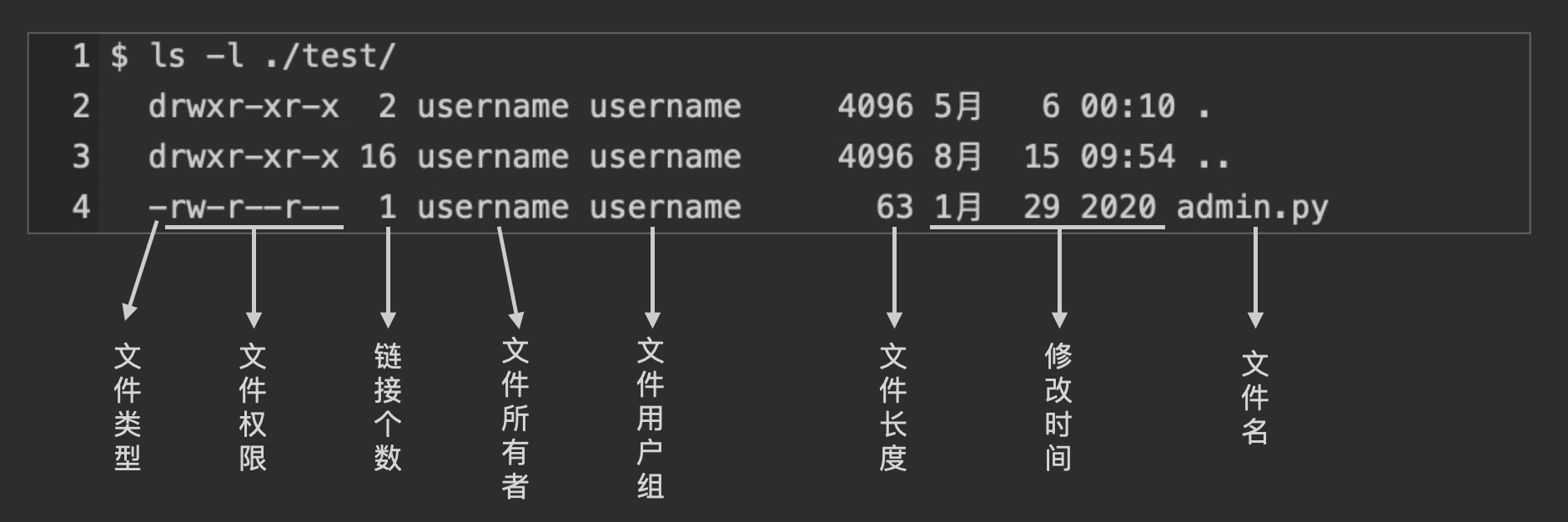
$ ls -al ./test/
drwxr-xr-x 2 username username 4096 5月 6 00:10 .
drwxr-xr-x 16 username username 4096 8月 15 09:54 ..
-rw-r--r-- 1 username username 63 1月 29 2020 admin.py
-rw-r--r-- 1 root root 177 1月 30 2020 test.py
-rw-r--r-- 1 root root 6561 1月 29 2020 test.log
理解了上面这些知识,就能理解目录的权限:
- 目录文件的读权限(r)和写权限(w)针对目录文件本身
- 由于目录文件内只有文件名和inode号码,如果想读取目录项的inode内容,Linux规定需要用户拥有目录的可执行权限(x)
设备文件
ls -l 命令下,第一个字段中的第一个字符是表示文件的类型,除了普通文件和目录文件,还有设备文件、链接文件和管道文件
| 字符 | 代表的文件类型 |
| - | 普通文件 |
| d | 目录文件 |
| l | 链接文件 |
| b | 块设备文件 |
| c | 字符设备文件 |
| s、p | 关系到系统的数据结构和管道文件,很少见 |
软链接与硬链接
硬链接
一般情况下,文件名和inode号码是”一一对应”的。但是,Linux系统允许多个文件名指向同一个inode号码,也就是硬链接(hard link)
一旦建立硬链,就不再区分则源文件与硬链文件的概念,二者是指向相同inode的“平等的两个文件”(如果以文件名区分)。由于指向相同的inode,硬链接的行为就很好理解了:
- 如果修改文件内容,则通过其他文件名访问的内容也随之修改
- 如果删除文件,则系统检查是否还有其他文件名指向inode。如果没有,则删除inode与block;否则,仅删除当前文件名到inode的映射
使用 ln <src> <hard_link> 命令创建硬链接
$ ln example.txt example_2.txt
$ ls -li
总用量 20
261774 -rw-rw-r--. 2 root root 4847 3月 9 22:55 example_2.txt
261774 -rw-rw-r--. 2 root root 4847 3月 9 22:55 example.txt
261779 drwxrwxr-x. 3 root root 4096 3月 9 23:16 exp_dir
第一列是inode号,第3列是指向该inode的文件名的数量,即链接数。可见,example.txt、example_2.txt的inode号都为261774,共有2个文件名指向inode 261774
顺便说一下,“.“和”..“也是目录,通过硬链分别指向当前目录和父目录。因此,所有目录的链接数必然大于等于2,即当前目录和”.”目录。如上,exp_dir目录的链接数为3
软链接
硬链使用起来不是那么方便,管理起来也比较麻烦。于是使用另一种更简单的方式实现了软链(soft link,或称符号链接symbolic link):如果文件A软链指向文件B,则标记文件A为软链文件,并在文件A中记录文件B的路径
此时,文件A与文件B使用不同的inode。那么,如何通过文件A访问到文件B的内容呢?操作系统会在我们访问文件A时,发现文件A是软链文件,则自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B
对于读、修改操作,硬链接与软连接实现的效果相同。但删除(包括rename)操作上的表现不同:
- 如果删除文件A,则文件B无影响
- 如果删除文件B,则文件A依然存在,但访问文件A时会报错”没有那个文件或目录”
使用 ln -s <src> <soft_link> 命令创建软链接
$ ln -s example.txt example_3.txt
$ ls -li
总用量 20
261774 -rw-rw-r--. 2 root root 4847 3月 9 22:55 example_2.txt
261782 lrwxrwxrwx. 1 root root 11 3月 10 00:05 example_3.txt -> example.txt
261774 -rw-rw-r--. 2 root root 4847 3月 9 22:55 example.txt
261779 drwxrwxr-x. 3 root root 4096 3月 9 23:16 exp_dir
可见, example_3.txt是软链接文件,指向example.txt,二者的inode号码不同,链接数也没有关系
管道文件
Linux上还有一类更特殊的文件类型被称作“管道文件”,也是我们在学习Linux命令行的时候就会引入的一个很重要的概念。
管道文件的发明人是道格拉斯.麦克罗伊,也是UNIX上早期shell的发明人。他在发明了shell之后,发现系统操作执行命令的时候,经常有需求要将一个程序的输出交给另一个程序进行处理,这种操作可以使用输入输出重定向加文件搞定,比如:
$ ls /etc/ > etc.txt
$ wc -l etc.txt
但是这样未免显得太麻烦了。所以,管道的概念应运而生。目前在任何一个shell中,都可以使用“|”连接两个命令,shell会将前后两个进程的输入输出用一个管道相连,以便达到进程间通信的目的:
$ ls -l /etc/ | wc -l
对比以上两种方法,我们也可以理解为,管道本质上就是一个文件,前面的进程以写方式打开文件,后面的进程以读方式打开。这样前面写完后面读,于是就实现了通信
实际上管道的设计也是遵循UNIX的“一切皆文件”设计原则的,它本质上就是一个文件。Linux系统直接把管道实现成了一种文件系统,借助VFS给应用程序提供操作接口
虽然实现形态上是文件,但是管道本身并不占用磁盘或者其他外部存储的空间。在Linux的实现上,它占用的是内存空间。所以,Linux上的管道就是一个操作方式为文件的内存缓冲区
匿名管道与命名管道
匿名管道最常见的形态就是我们在shell操作中最常用的”|”。它的特点是只能在父子进程中使用,父进程在产生子进程前必须打开一个管道文件,然后fork产生子进程,这样子进程通过拷贝父进程的进程地址空间获得同一个管道文件的描述符,以达到使用同一个管道通信的目的。此时除了父子进程外,没人知道这个管道文件的描述符,所以通过这个管道中的信息无法传递给其他进程
这保证了传输数据的安全性,当然也降低了管道了通用性,于是系统还提供了命名管道
我们可以使用mkfifo或mknod命令来创建一个命名管道,这跟创建一个文件没有什么区别:
$ mkfifo pip
$ ls
prw-rw-r--. 1 lizhipeng lizhipeng 0 11月 17 13:24 pip
文件类型标识符为 p,这表示它是一个管道文件。有了这个管道文件,系统中就有了对一个管道的全局名称,于是任何两个不相关的进程都可以通过这个管道文件进行通信了。比如我们现在让一个进程写这个管道文件:
$ echo xxxxxxxxxxxxxx > pip
此时这个写操作会阻塞,因为管道另一端没有人读。这是内核对管道文件定义的默认行为。此时如果有进程读这个管道,那么这个写操作的阻塞才会解除:
$ cat pip
xxxxxxxxxxxxxx
参考&扩展
Linux文件系统:inode&block,文件&目录,硬链&软链
硬盘类型和Linux分区
阮一峰的网络日志:理解inode
聊聊 inode 为什么会耗尽