Linux的文件系统(2)——硬盘分区、文件系统与硬盘挂载
在文件系统的底层,操作系统通过设备文件、分区、LVM等一步步抽象,最终以挂载到文件系统为终点,完成从物理硬盘到软件系统的交接
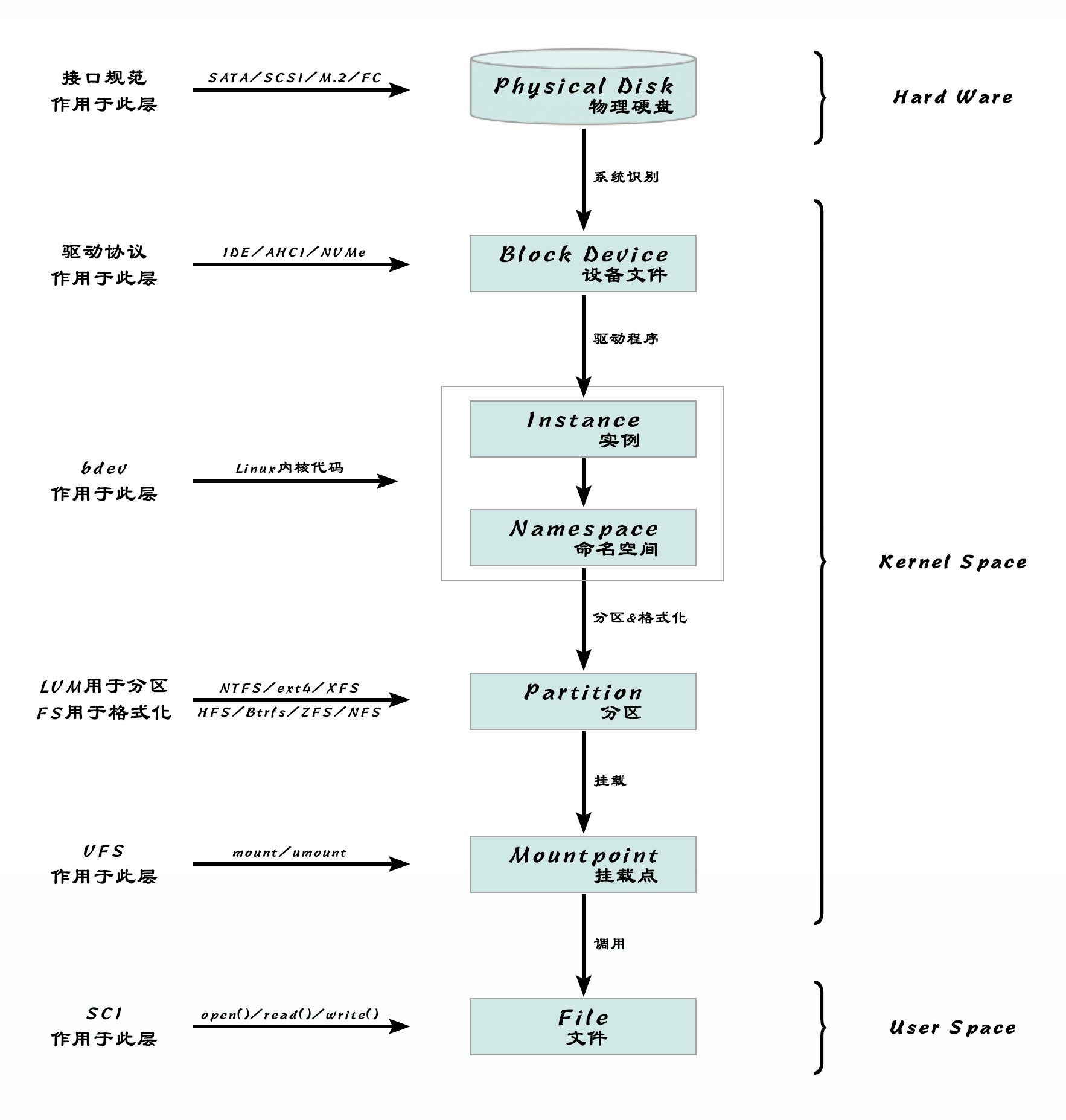
硬盘分区
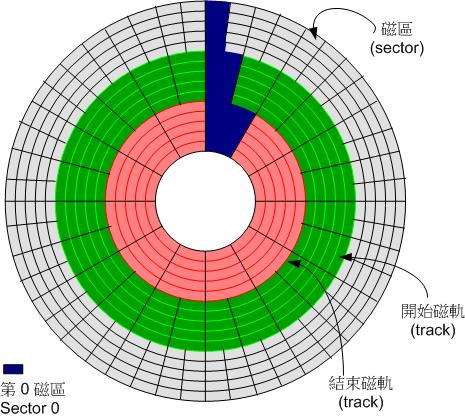
传统的机械硬盘(HDD)以扇区(sector)为单位存储内容,常见一个扇区 有512B的存储空间。不过这个大小不是物理限制,而是约定俗成,企业级的硬盘也会使用4KB大小的扇区
传统硬盘(磁盘)盘片组成与扇区示意
在硬盘的第一个扇区中,存储着硬盘的启动程序和分区信息表:记录硬盘上各个分区所对应的物理扇区信息,如果它受到破坏,将无法访问硬盘上的数据信息(用繁琐的方式试探性的重建结构信息才有一定几率能重新访问到原先的数据)
硬盘启动的时候首先读取第一扇区中的启动程序和分区表,目前的分区表有两种格式:MBR和GPT
MBR(Master Boot Recor)
MBR直译即“主引导记录”,最早是Widonws用来处理启动程序和分区表的方式,早期Linux为了相容Windows的磁盘,也支持和使用MBR
MBR占用一个扇区(512B)的空间。其中446B存放了启动程序,剩下64B的固定空间用于存放分区表,因此最多能支持四组记录信息,即四个主分区(Primary),或三个主分区(Primary)+一个扩展分区(Extended)
所谓 扩展分区(Extended) 就是既然分区表中只能存放四组记录,那我们在自己的分区下继续细分(相当于二级分区),并用额外的扇区来记录分区信息就好了。最多只能有一个分区被允许这样细分,这个分区就被称 扩展分区,而被继续细分出来的分区被称为 逻辑分区(Logical)
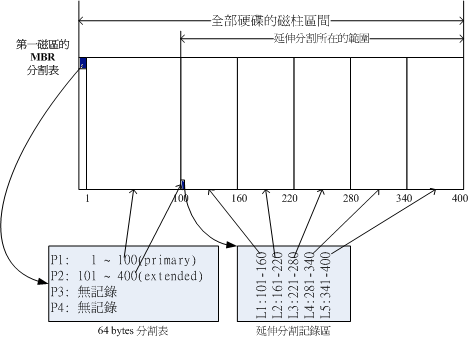
上图中MBR中的四个记录空间仅用到两个:一个主分区+一个扩展分区,扩展分区又继分为五个逻辑分区,并用自己的第一个扇区来记录逻辑分区的分区表信息
在Linux系统中,MBR硬盘分区命名为sda[1-4]或者hda[1-4]等,1-4是主分区(或者扩展分区),逻辑分区号从5开始:sda[5-9]或hda[5-9]等
GPT(GUID Partition Table)
由于MBR分配给分区表的空间只有64B,每一个单独的分区记录信息大小不能超过16B,这限制了每个分区的大小不能超过2.2TB(16B能表达的最大扇区数也就232,再乘以扇区大小512B,约等于2.2TB)
为了解决这一问题,就有了GPT分区表:使用GUID(通用唯一识别码)的分区表:
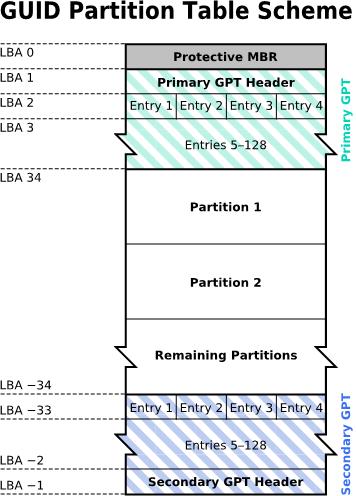
GPT使用34个LBA(逻辑区块)来存放分区信息,其中每个LBA都有512B的大小!第一个LBA0用来兼容传统MBR(446B的启动程序+一个特殊的标志信息,表明此磁盘为GPT格式),从第二个LBA开始记录GPT的分区表信息
每个LBA有512B的大小,可以记录4笔分区信息,因此每个分区信息可用到128B的空间,每个分区的大小可有9.4ZB!
除了开头的34个LBA以外,GPT还用整个磁盘的最后33个LBA作为分区表信息的备份,这与MBR一旦受到破坏就难以恢复相比,无疑是增加了一层安全保障
GPT没有所谓的主分区、扩展分区、逻辑分区的的概念,每一个分区都等同于主分区。在Linux系统中,GPT硬盘分区的命名可支持后缀[1-128],甚至更多
Swap分区
程序在运行时所有数据是在内存(RAM)中,当内存被耗尽或者使用量超过了限额,系统就会停止程序
为了使系统更稳定,在硬盘上划分一部分空间来做内存缓冲区,当内存使用超过限额,内核会把内存中闲置的数据放到缓冲区中;当程序需要缓冲区中的数据时,内核将缓冲区中的数据再交还给内存进程处理
Linux系统使用Swap分区作为硬盘上的缓冲区,用户可以通过 mkswap 命令来将一个分区格式化为Swap分区,格式化的对象可以是某一实体分区,也可以是软件模拟的伪设备分区(比如Loop设备文件)
$ mkswap /dev/sdb1
Setting up swapspace version 1, size = 524284 KiB
no label, UUID=6b17e4ab-9bf9-43d6-88a0-73ab47855f9d
$ blkid /dev/sdb1
/dev/sdb1: UUID="6b17e4ab-9bf9-43d6-88a0-73ab47855f9d" TYPE="swap"
将sdb1分区格式化为Swap格式,并用blkid查看信息
在Windows中,不会为缓冲区单独划分一个Swap分区,而是使用分页文件实现相同的功能,Windows称其为虚拟内存
早期计算机的内存空间有限,所以Swap分区十分重要。一般来讲,Swap分区容量应大于物理内存的大小,建议是内存的两倍,但不要超过4G
现代计算机飞速发展,内存动辄64G或者更多,这时Swap分区就已经不再必须了:这么大的内存哪怕真不够用了,把几十G的数据向硬盘上转移,之后再读回来,I/O负载已经得不偿失了
所以有的系统会直接禁用Swap。当然,另一种情况比如你跑的某些程序(比如Oracle)就是很吃内存,有多少内存吃多少内存那种(无论内存多大),那设置Swap可以起到一定的保障作用。具体问题具体分析(你如果就是租了个1G内存的ECS来当服务器,那肯定要开Swap啊)
NVMe硬盘的分区
固态硬盘(SSD)与传统硬盘(HDD)有着完全不同的底层结构和工作模式:固态硬盘没有扇区的概念,以页(Page)为单位读取数据,以块(Block)为单位修改数据,同时还会进行磨损均衡、垃圾回收等处理,要远比传统硬盘复杂

固态硬盘(SSD)数据读写示意图
不过目前几乎所有的固态硬盘,都屏蔽了底层复杂的实现细节,都表现为一个和机械硬盘一样的存储设备,所以我们可以使用 一样的分区存储模型
$ ls -1 /dev/nvme*
/dev/nvme0
/dev/nvme0n1p1
/dev/nvme0n1p2
在 /dev/ 目录下查看NVMe硬盘设备可以发现与传统硬盘已经有了区别。NVMe的驱动程序会先创建一个字符设备 /dev/nvme0,再通过 nvme_dev_start 函数完成其初始化,最后通过 nvme_dev_add 函数向系统注册块设备,即 /dev/nvme0n1p1 和 /dev/nvme0n1p2(p1和p2为该块设备的分区)
/dev/nvme0 文件在一些资料中被称为 NVMe Controller 或 NVMe Instance,具体实现细节可参考 linux内核源码分析 - nvme设备的初始化
目前,一些针对固态硬盘的新技术提案甚至会不再使用LBA(逻辑区块)的概念。那么也许有一天,我们就会看到另一种,全新的,不同于MBR和GPT的分区存储模型了
至于硬盘一定要分区吗?其实是不一定。只是分区是有很大的好处:
1. 数据的安全性与操作方便:每个分区的数据是分开的,比如Windows中当你重装C盘的时候不会影响D盘!
2. 系统性能的考虑:同一分区的数据集中在相邻的扇区内,这有助于分区内数据读取的性能(局部性原理)
3. 挂载点与文件系统:不同的分区可以针对各自的挂载点灵活的使用不同的文件系统
LVM
类Unix系统的一个特点就是通过 设备文件 抽象了物理设备,所有的硬件设备都像文件一样看待
那么硬盘分区是否也可以进行一步抽象,即在物理硬盘的分区上再抽象出一个 逻辑层:所有的物理硬盘全部视为一个整体资源,所有的分区工作都在逻辑层之上进行,这便是LVM(Logical Volume Manager)
LVM有很多好处,之后的分区调整都避免了对物理硬盘的分区进行直接操作。毕竟物理硬盘的分区一旦划定,调整起来就相当麻烦,而建立在逻辑层之上的逻辑分区就很灵活。下面是LVM的体系结构:
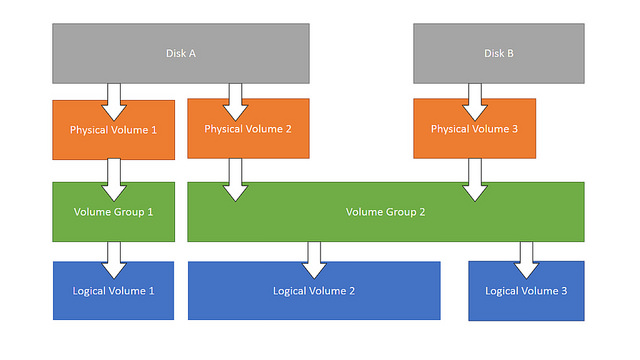
物理硬盘 ——> 物理卷(硬盘分区)——> 逻辑层(卷组)——> 逻辑卷(逻辑分区)
我们将原来的物理硬盘及其分区称为 物理卷(PV),而逻辑层上的分区称为 逻辑卷(LV),一个逻辑卷可以整合多个物理卷。逻辑卷可以随意的扩展、伸缩,而不用担心对物理卷的影响
在Linux中使用和管理LVM的方法可参见 Linux LVM简明教程
硬盘挂载与VFS
无论是物理分区还是逻辑分区,硬盘的最终归宿都是挂载
硬盘只有挂载到文件系统后才能更好的使用。Windows是自动挂载,Unix类的操作系统是通过 mount 命令实现,挂载时要有挂载点,通常是一个空置的目录。常见的命令如下:
$ mount /dev/fd0 /media/floppy
挂载点是一个空目录,(若不存在,需要先建立一个空目录),mount 后该目录中的内容就是你载入的设备文件的内容
如果挂载点不是一个空目录,mount新设备后原目录的内容将被隐藏,umount后可恢复
一个设备分区可以mount到多个挂载点,但一个挂载点只能挂载一个设备分区
其实我们也可以直接对 设备文件 进行操作,比如我们已经可以看到在 /dev/ 目录下的设备文件,那就是已被操作系统识别并关联(某种意义上也就是挂载)到Linux目录树上的了
Linux 创建了一种只运行在内存中的 bdev文件系统,用来管理这些设备文件。我们可以通过合适的编程,了解bdev的实现细节,直接对设备文件进行操作。但这样我们就不能使用我们常见的 open(),close() 等一系列的文件操作了,因为这些都是Linux为我们抽象出的更上一层的文件系统——VFS(Virtual File System)所提供的API
Linux文件系统的层次结构——从硬盘到VFS:
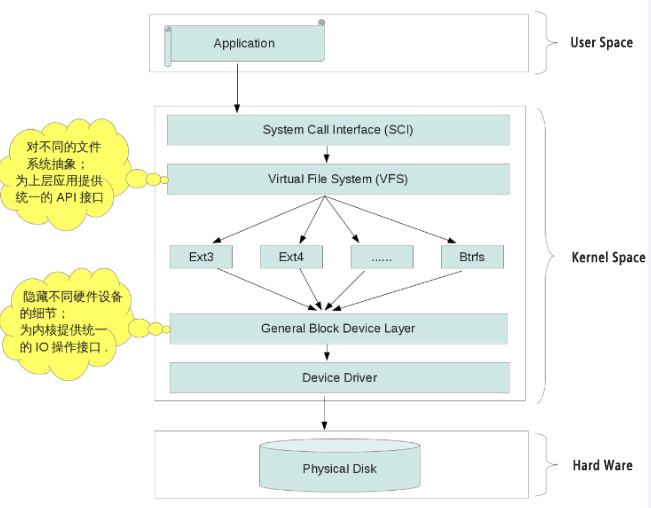
物理硬盘 ——> 硬盘驱动(Device Driver)——> 设备文件(Block Divice) ——> 不同的文件系统 ——> 虚拟文件系统(VFS) ——> 系统调用 ——> 用户应用
硬盘挂载的过程,就相当于我们把 /dev/ 下的 设备文件,挂载到Linux的 文件系统(VFS) 中。到了这一步,我们才真正的可以在用户空间的层面操作硬盘上的文件了
VFS相当于对设备文件及不同设备文件上可能并不相同的文件系统做了一个整体抽象,屏蔽底层细节,然后再向用户空间提供统一的API访问接口。这时,用户便可以通过 系统调用 来操作不同的文件了
fstab配置文件
fstab文件用于配置Linux系统中的自动挂载(开机挂载),位于/etc/fstab
$ cat /etc/fstab
# Device Mount point filesystem parameters dump fsck
#[设备/UUID] [挂载点] [文件系统] [参数] [dump] [fsck]
/dev/mapper/centos-root / xfs defaults 0 0
UUID=94ac5f77-cb8a-495e-a65b-2ef7442b837c /boot xfs defaults 0 0
/dev/sda2 /home xfs defaults 0 0
/dev/sda6 swap swap defaults 0 0
UUID=e0fa7252-b374-4a06-987a-3cb14f415488 /data/xfs xfs defaults 0 0
一般推荐使用UUID来标识设备而不是设备名(如/dev/sda2这种),因为设备名每次重新开机可能会因为硬盘所插的位置变化而变化
可使用 blkid 或 xfs_admin 来查询UUID
使用 mount 命令时,系统可以自动匹配设备的文件系统。但在fstab文件中必须手动指定每个设备的文件系统
dump 参数是一个用于做备份的指令,现在基本不用了,写0就行
fsck 参数为是否使用 fsck 检验扇区,用以查看文件系统是否完整(clean),现在也基本不用了,写0就行
fstab文件修改后不会立即生效,可用 mount -a 重新强制读取fstab文件
$ mount -a
同时,及时的 mount -a 也可以测试 fstab 内容的语法是否正确。fstab文件及其重要,根目录的挂载也在其中。如果内容配置不当,会导致无法正常进系统。这时需要使用超级用户,进入单人维护模式当中,用下面的命令重新手动挂载根目录:
$ mount -n -o remount,rw /
UUID
UUID(universally unique identifier),即全域单一识别码,Linux 会将系统内所有识别的设备文件都给予一个独一无二的识别码,这个识别码可以拿来作为挂载或者操作这个设备等使用
过去我们都习惯使用设备文件名,并直接用该文件名挂载硬盘。但更建议的方式是使用UUID。设备文件名可能会因为一些操作而产生变化,而UUID是永远独一无二的
常见的文件系统格式
Linux使用VFS统一了所有底层的文件系统格式,但有时候我们还是需要知道不同文件系统之间的区别
买回一个新的硬盘,分区完毕后往往对每个分区还要进行格式化(format)。这个格式化的操作就是赋予硬盘分区具体的文件系统的过程
文件系统决定了硬盘设备中软件层面的文件存储模型(拓扑结构)
常见的文件系统格式有:
- FAT12、FAT16、FAT32(Windows)
Windows 98及以前的Windows系统使用的文件系统格式。很长一段时间内FAT32都是软盘、硬盘和U盘上最常见的文件系统格式 FAT32最大的问题是支持单个文件最大大小为4G,分区最大容量为8T,这在当下的计算机环境中显然是不够看的 - NTFS(Windows)
Windows 2000及以后的Windows系统的默认文件系统格式,是Windows系统第一款支持日志的文件系统,最大单个文件大小16EB,支持ACL Mac或Linux系统下只支持对NTFS格式的只读。如果想写入NTFS硬盘需要安装额外的软件(如Paragon NTFS,但也不稳定) - exFAT(Windows/Linux/Mac)
即Extended FAT,是微软专为U盘设计的文件系统格式,扩展于FAT,单个文件大小支持16EB,分区大小支持64ZB。优点是支持Windows、Linux、Mac系统,是目前移动硬盘/U盘上比较合适的文件系统格式 - ReFS(Windows)
微软在Windows Server 2012中引入的文件系统格式,针对大存储系统(如RAID)做了优化,同时通过自检查功能提升了数据的可靠性。目前只见于Windows Server系列和Workstation系列产品中,未来可能会取代NTFS - ext2、ext3、ext4(Linux)
Linux的文件系统格式,目前发展到第四代。从ext3开始支持日志。Windows和Mac系统都不支持ext系列的文件系统(可安装Paragon ExtFS软件来支持,但也不稳定) - Reiserfs (Linux)
Linux的文件系统格式,曾经因Novell公司的支持而用在某些Linux版本中,现在已经全面被ext系列所取代 - JFS(Linux)
IBM为其AIX操作系统开发的一种文件系统格式,第二代开始可以被移植到Linux系统当中。可能是最早使用日志的一种文件系统格式。目前基本只在IBM Linux的机器上见到 - XFS(Linux)
Linux的文件系统格式,CentOS 7等Linux发行版本中将XFS设为默认的文件系统。相比ext系列,XFS在数据安全、磁盘分配、可扩展性、I/O处理等诸多方面都有优势 目前XFS的主要缺点是无法直接收缩卷大小(这也是很多云端主机供应商会告知用户存储空间只能增加不能缩减的理由之一),只能通过「备份—>调整—>还原」的方式进行容量缩减 - HFS、HFS+(Mac)
MacOS 10.12及以前的Mac系统所使用的文件系统格式,支持8EB的单个文件大小。Linux系统支持HFS但有限制或不稳定,Windows系统不支持HFS格式(可安装aragon HFS for Windows软件来支持) - APFS(Mac)
MacOS 10.13及以后的Mac系统所使用的文件系统格式,支持8EB的单个文件大小,针对SSD做了大幅优化。目前Linux系统还没有原生支持APFS,但已经有很多第三方软件可提供支持了 - Btrfs(Linux)
Oracle开发的文件系统格式,最初的目标是用来取代ext3。特点是使用B-tree作为底层的拓扑结构。OpenSUSE等Linux发行版使用Btrfs作为默认文件系统 - ZFS、OpenZFS(Solaris)
Oracle(Sun)为其Solaris操作系统开发的一种文件系统格式,特点是基于存储池的概念,与典型的映射物理存储设备的文件系统有很大不同,在动态调节上有很大优势 OpenZFS为ZFS的开源版,经过适配,可使用于类Unix系统中 - HPFS(OS/2)
IBM为其OS/2操作系统开发的一种文件系统格式,是NTFS的原型,微软与IBM在开发OS/2的过程中出现分歧才导致了NTFS的出现。Linux和FreeBSD等类Unix系统也支持HPFS格式 - iso9660、UDF(光盘文件系统)
iso9660也被称为CDFS或ECMA-119,UDF也被称为ECMA-167,是光盘的统一文件系统格式,适用于所有操作系统。iso9660支持单个文件最大大小为4G,UDF支持单个文件最大大小为16EB,目前iso9660已被UDF所取代 - VFAT(Windows)与vfat(Linux上的一种表示)
即Virtual FAT,FAT32之前的FAT文件系统不能支持超过8个字符长度的主文件名和超过3个字符长度的扩展文件名(即8.3命名规范),于是Windows 95的设计人员创造了VFAT文件系统格式,用于突破这一限制。在FAT32随着Windows 95 OSR2发布后,VFAT停用 早期的Linux系统为了兼容Windows的FAT系列文件格式,曾使用一种名为umsdos的文件格式,即带有Unix文件属性(如长文件名和访问许可)的FAT。随着VFAT的发布,增加了这些新属性,于是Linux直接支持了vfat。后来FAT系列更新到FAT32,Linux系统中对其的名称并没有改变,依然叫vfat。所以Linux系统中的vfat可以理解为VFAT及之后的Windows FAT系列文件系统格式的统一表示 - Minix FS(Minix)
Minix操作系统中所使用的文件系统格式,早期Linux也使用这一文件系统,后被ext2所取代 - NFS、SMBFS、CIFS、GFS、GFS2(网络文件系统/分布式文件系统)
一系列的网络文件系统或分布式文件系统格式,目标是实现从客户端主机可以访问服务器端文件,并且其过程与访问本地存储时一样。可参见 搭建 NFS 服务器 - F2FS
Linux的文件系统格式,针对SSD设计,由三星集团开发,目前见于Android移动设备之中
使用 df 或 lsblk 命令来查看Linux系统中的FAT32格式硬盘,只会看到 vfat 的格式,但用 sudo file -sL /dev/sda1 命令则可以看到 FAT (32 bit)
现代文件系统的实现已经非常复杂了,不是三言两语能说清楚的。文件系统更多的类型与细节,可参见 Comparison of file systems
Linux目前几乎支持所有的Unix类的文件系统,如 HFS、XFS、JFS、Minix fs等。Linux 也支持 NFS 文件系统。Linux 也支持 NTFS 和 vfat,但不支持 NTFS 的写操作。具体查看本机Linux 支持的文件系统,可查看下面的文件
$ ls -l /lib/modules/$(uname -r)/kernel/fs
查看系统目前已载入(注册)的文件系统则使用:
$ cat /proc/filesystems
文件系统不关心自身放在哪一个物理设备的哪一个区块上,那是设备驱动程序的工作。只要提到文件系统,就可以看做其中所有节点都是可供操作的文件
目前的存储设备容量更新很快,SSD硬盘逐渐取代HDD硬盘,新的文件系统格式也会逐步取代旧的文件系统格式
/proc/下的虚拟文件
/proc/ 下的虚拟文件真实地体现了Linux VFS系统的特点。该目录和它的子目录中的内容并不真正的存在于物理硬盘上,它们只存在于内存中
但 /proc/ 依然向VFS文件系统登记了这些节点,像一个真正的文件系统目录一样
当我们试图访问这些文件的时候,Linux才根据内核中的信息创建出文件内容。例如 /proc/cpuinfo 是保存 CPU 信息的,/proc/devices 是当前设备驱动的列表,/proc/filesystems 是当前注册的文件系统列表,/proc/net 是描述网络协议信息的......
/proc/ 代表着一个用户可读的窗口,用于察看Linux核心的内部工作空间
S.M.A.R.T.
S.M.A.R.T.是一种硬盘自监测技术,全称为“Self-Monitoring Analysis and Reporting Technology”,即自我检测、分析及报告。最初应用于机械硬盘当中,通过在硬盘硬件内的检测指令对硬盘的磁头、盘片、马达、电路等运行情况实时监控,并与预设的安全值进行比较,一旦情况将要或已超出预设安全值的安全范围,就可以通过主机的监控硬件或软件自动向用户作出警告并进行轻微的自动修复
S.M.A.R.T.很快成为所有机械硬盘的标配,固态硬盘(SSD)出现之后,也延续使用了S.M.A.R.T.来表示硬盘的健康信息。当然,底层的实现和检测的参数已经完全不同了
Linux中可以使用 smartctl 工具来读取硬盘的S.M.A.R.T.信息(不分机械硬盘还是固态硬盘):
# smartctl 作为第三方软件需要先安装,这里以 CentOS 为例
$ sudo yum install smartmontools
# 运行以下命令查看硬盘信息
$ smartctl -a /dev/sda
总结
粗略的总结一下存储设备在Linux系统下,从物理硬盘到文件节点的大致过程(仅示意,具体细节其实是不太准确的):
参考&扩展
Device Mapper 的原理
DOCKER基础技术:DEVICEMAPPER
DOCKER基础技术:AUFS
Linux LVM简明教程
SSD下一阶段演化:分区存储
Linux swap分区及作用详解
The Linux Kernel documentation
linux内核源码分析 - nvme设备的初始化
蛋蛋读NVMe
块设备文件与文件系统的关系
UUID 是如何保证唯一性的
《Linux Kernel核心中文手册》—— 第 9 章 文件系统
技术摘要| Linux 文件系统不专业评测
关于XFS文件系统概述
FAT、HPFS 和 NTFS 文件系统概述
Filesystems in the Linux kernel
Linux下的FAT文件系统格式
CIFS和NFS
搭建 NFS 服务器
Comparison of file systems
还在用EXT4?拥抱F2FS实战
文件系统和 ACL 支持
官网:smartmontools
Virtual filesystems in Linux 详解
Linux 下启用 SSD TRIM 功能
Linux 文件系统
25张图一口气搞懂Linux文件系统
深入理解基于Linux文件系统原理与实现