
基于用户投票的排名算法整理
拥有媒体属性的网站,如微博,拥有UGC性质的网站,如知乎,拥有流量分发性质的页面,如蚂蜂窝自由行。往往都要考虑一个问题:首页展示哪些信息
要在繁多庞杂的网站内容中过滤出用户真正关注的内容,并不容易,所以人们发明了各式各样的排名算法。之前著名博主阮一峰曾经写过一系列广为流传的介绍排名算法的文章。这篇文章主要是对那一系列文章的学习和整理。引用与图片来源均已标明
一切的基础:赞同、反对和时间
在基于用户投票的排名算法里,赞同、反对和时间,是一切的基础。这是因为基于用户投票的排名算法的目标是:为用户展现新的以及好的内容。赞同与反对反应了内容好坏,而时间反应了内容新旧
内容的新旧比较好决定,通常,时间的倒数就可以表示
内容的好坏比较难决定,通常代表赞同的正反馈包括:浏览、收藏、点赞、评论、分享、关注等;代表反对的负反馈包括:点踩、差评等
基于赞同、反对和时间可以得到排名算法的基本公式:
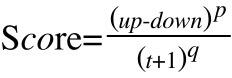
其中,
up是赞同数量
down是反对数量
t是距离发帖的时间,加上1是为了避免分母为0,以及分母小于1时整体score的翻倍影响
p是正反馈权重,即将“好的内容”排名往上提的力量
q是负反馈权重,即将“旧的内容”排名往下拉的力量
旧版Delicious的算法
它按照"过去60分钟内被收藏的次数"进行排名。每过60分钟,就统计一次。
这个算法的缺陷是对时间的处理过于粗暴,排名变化不够平滑,每过一小时就与前一小时毫无关系。而且缺乏自动淘汰旧项目的机制,某些热门内容可能长期占据排行榜前列
Haker News的算法
关于Haker News的算法讨论非常多,目前可以在这里看到源代码及相关讨论:HN ranking algorithm:
公式: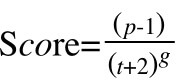
其中,
p是帖子的票数,减去1是为了忽略发帖人的投票
t是距离发帖的时间,加上2是为了避免分母过小时的影响
g是“重力因子”,即将“旧的内容”随时间下拉,就像重力一样
可以看到Haker News就是上面提到的基本公式的一个真实写照,由于其没有反对按钮,所以其分子上只有代表赞同数量的p
当其他值不变时,得票越高,排名越高(图片来源:http://amix.dk/blog/)
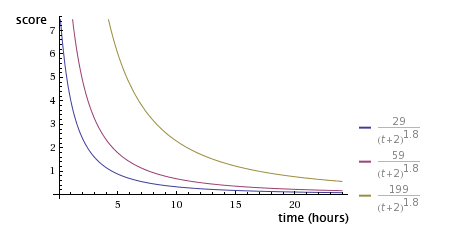
当其他值不变时,距离发帖时间越久,排名越低(图片来源:http://amix.dk/blog/)
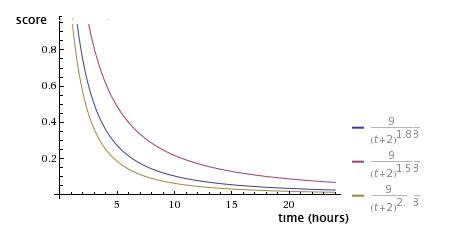
如果觉得投票数对帖子排名的影响太大,帖子之间的差距太大,可以在得票数上加一个小于1的指数,比如(p-1)0.8 。如果觉得时间对于帖子排名的影响过大,可以改变重力因子g的值,这两个值可以根据产品反馈不断调整
Stack Overflow的算法
像Haker News这样的网站,用户只能点赞同票,也就是说,除了时间因素外,我们只要考虑赞同的因素就好了。而有更多的网站,必须要考虑更多的东西,比如Stack Overflow
Stack Overflow是一个问答类型的网站,访问者可以对提问者提出的问题投赞同票,也可以投反对票,还可以进行回答。一旦有人回答了你的问题,其他人也可以对这个回答投票(赞成票或反对票)
排名算法期望找到当前时段,哪些问题得分更高、被讨论更多、以及被提供了更有价值的回答,这需要考虑问题评分、浏览数量、讨论数量、回答得分四个因素,创始人之一的Jeff Atwood,公布过排名得分的计算公式
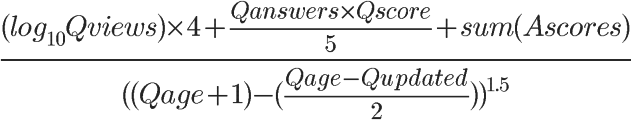
看起来是复杂了一点,但也只是看起来复杂了一点而已
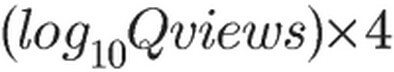 是问题的浏览次数,
是问题的浏览次数,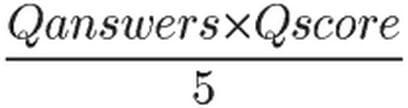 是问题的赞同数量和回答数量,
是问题的赞同数量和回答数量,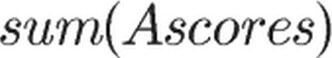 是问题的回答得分之和
是问题的回答得分之和
以上,构成了该排名算法的正反馈
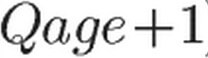 是距离问题发表的时间,
是距离问题发表的时间,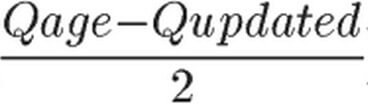 是问题在多长时间前更新过
是问题在多长时间前更新过
以上,构成了该排名算法的负反馈
上面三个例子为我们展示了基于赞同、反对和时间的排名算法的基本逻辑,从简单到复杂,通过反馈可以不断调节正反馈和负反馈的“权重因子”,以及不断细化正负反馈的来源,使算法不断趋向于我们想要的结果
抑制马太效应
基于赞同、反对和时间的排名算法通常面临的一个问题被称为“马太效应”
马太效应典出《马太福音》:凡有的,还要加给他,叫他有余;凡没有的,连他所有的也要夺去。
马太效应体现在社会生活的方方面面,由“反馈叠加”导致了“贫者愈贫富者愈富”的现象,最终产生“两极分化”。在排名系统里的体现则是:热门的内容被顶到排行榜头部,从而被更多的人预览,从而获得更高的浏览量进而获得了更好的排名。而冷门的内容从来没有机会出现在排行榜上
排名算法必须避免这种情况的产生,通常我们有以下几种方法:
增加影响维度
上面的例子中,Haker News的算法比较容易产生马太效应,因为其维度比较单一,除了时间,只有帖子的投票数对排序有影响
抑制马太效应的第一个方法是增加排序的影响维度,比如Stack Overflow的算法中有四个影响维度,再比如下面的Reddit算法中,用户除了点赞同票,还可以点反对票,解决了流动的单向性,避免帖子只能上升不能下降
Reddit的算法
Reddit是美国较大的网上社区,它的每个帖子前面都有向上和向下的箭头,分别表示"赞成"和"反对"。Reddit的代码也开源了,目前可以在这里看到源代码:github-reddit
公式:(来源:https://moz.com/blog/)
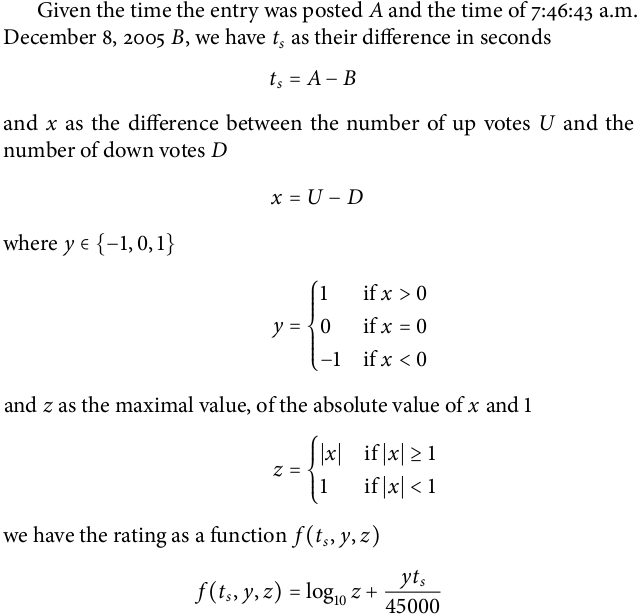
其中,
z是绝对得分,即赞同票数减去反对票数的绝对值
y是投票趋势,如果赞同票数大于反对票数,y=1,如果赞同票数小于反对票数,y=-1,如果赞同票数等于反对票数,y=0
t是发帖的时间距离2005年12月8日7时46分43秒的秒数
Reddit在基于赞同、反对和时间的算法上做了2点优化:
- 抑制了马太效应:正反馈为投票数绝对值的对数值:
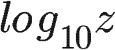 ,也就是说,前10个投票人与后90个投票人(乃至再后面900个投票人)的权重是一样的,即如果一个帖子特别受到欢迎,那么越到后面投赞成票,对得分越不会产生影响。
,也就是说,前10个投票人与后90个投票人(乃至再后面900个投票人)的权重是一样的,即如果一个帖子特别受到欢迎,那么越到后面投赞成票,对得分越不会产生影响。 - 副反馈不再以分母的形式存在,而根据投票趋势影响投票:
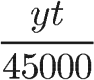 ,当用户投票趋势是赞同时,时间起到加分作用,越新的帖子得分越多。当用户投票趋势是反对时,时间起到扣分作用,越新的帖子扣分越多。这保证了得到大量净赞成票的帖子排在前面,而反对票多的帖子,会迅速滑落到排行榜尾。
,当用户投票趋势是赞同时,时间起到加分作用,越新的帖子得分越多。当用户投票趋势是反对时,时间起到扣分作用,越新的帖子扣分越多。这保证了得到大量净赞成票的帖子排在前面,而反对票多的帖子,会迅速滑落到排行榜尾。
Raddit排序算法有一个问题:扩大了反对票的影响。当一个新帖子出现,尚未获得足够多的赞同的时候,少量的反对将产生巨大的不利影响。并且那些有争议的文章:反对票和赞同票相当的帖子,不可能排在前面,z值太小。
时间因素
抑制马太效应的另一个有效方法是利用时间因素:将足够老的帖子拉下排行榜,增加新帖子的机会
上面的所有算法都考虑到了时间因素,包括老的Delicious算法,这些都使得足够老的内容不会长期占据排行榜头部的位置。关于时间因素,阮一峰的系列文章中提到了“牛顿冷却定律”
一个物体所损失的热的速率与物体和其周围环境间的温度差是成比例的
公式:
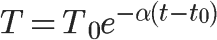
其中,
T0是初始分数
e是自然对数
α是冷却系数
t-t0表示距离发帖的时间
根据牛顿冷却定律的算法,一篇帖子的初始积分会根据时间的流逝不断“冷却”。考虑到了时间因素,越早的信息,比如赞同数量就越不重要,而越新的信息,所起到的影响就越大,抑制了马太效应
冷门内容的置信与公平
对于UGC社区来说,排名算法需要解决的另一个问题是:如何给相对冷门的内容一个相对公平的待遇?如果每一个帖子的投票数都差不多,当然好办,但当有一些冷门的内容投票数很少的时候,就会有各种各样的问题产生,主要包括以下两点:
样本空间过小,导致结果不可信,我们无法准确估计冷门内容的真正质量
比如一个帖子A,拥有80张赞同票和20张反对票,而帖子B拥有2张赞同票,没有反对票时,我们把帖子B排到帖子A的前面是不合适的,因为虽然B的赞同率更高,但样本空间过小参与人少的冷门内容无法与热门内容竞争,优质的冷门们内容无法获得出头机会
比如一个热门帖子总是有3000多投票,而相对冷门的帖子只有100多投票,考虑到样本空间大小的问题,数学模型上我们对第一个帖子永远有更准确的评估,进而鼓励其获得更高的排名,那么冷门的帖子将很难有机会出头,排名可能会长期靠后
威尔逊得分区间
二项分布
在概率论和统计学中,二项分布是n个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为p
如果每一次用户投票都是独立事件,并且每次投票只有两个选择,那么每次用户投票投赞同票的概率为p,显然这个p是符合二项分布的
置信空间
在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。置信区间展现的是这个参数的真实值有一定概率落在测量结果的周围的程度
对于二项分布的置信空间,常用的估计方法有两种:一是正态分布近似方法,即 Normal Approximation Method;二是精确置信区间法,即 Clopper-Pearson Method
正态分布
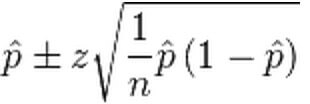
该方法的优点在于简单易于理解,但缺点在于当p接近0或1时精度会很差,当np > 5 或者 n(1-p)>5 时不推荐使用该方法。
精确置信区间法
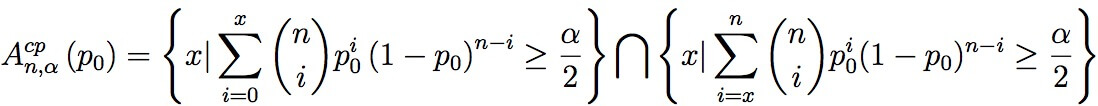
Clopper-Pearson法实际上并不是真正的“精确”置信区间,因为用于计算的k和n都必须为整数,其对置信区间的估计要比真实值更加保守。Wilson Method 和 Modified Wilson Method可以获得更好的结果
1927年,美国数学家 Edwin Bidwell Wilson提出了一个修正公式,被称为"威尔逊得分区间",很好地解决了小样本的准确性问题。
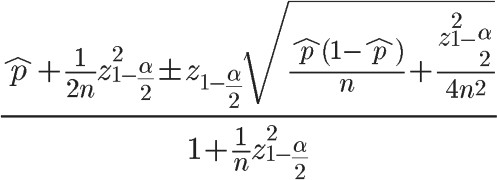
Wilson得分区间,当n足够大时其下限值趋近于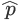 ,当n很小时,其下限值远远小于
,当n很小时,其下限值远远小于
利用威尔逊得分区间的下限值可以在排名中加入“置信度”的信息,使小样本的得分更合理。数学上,还有一些其他的关于二项分布的置信区间的估算方法,可参考:Binomial proportion confidence interval
IMDB的贝叶斯平均
如果考虑了置信空间,很多冷门的项目评分将被大幅拉低,导致参与人少的冷门内容无法与热门内容竞争,优质的冷门们内容无法获得出头机会
为了让冷门项目拥有更公平的竞争机会,可以使用“贝叶斯平均”
贝叶斯平均是指根据贝叶斯推导进行全局估算的方法:即使用额外信息进行数据估算,来修正数据偏移。或在样本数据集很小的时候,使用可能的断言,扩大样本集范围
公式: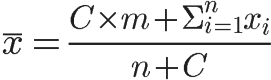
其中,
C是期望每个项目拥有的投票数
n是当前项目实际拥有的投票数
m是所有项目的平均得分
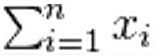 是该项目目前投票的得分总和
是该项目目前投票的得分总和
根据贝叶斯推断: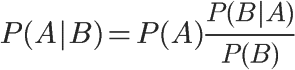 ,公式中的m相当于“先验概率”,每一次投票都是一个新的调整因子,使预估不断趋向于真实概率。因此,这种方法可以给一些投票人数较少的项目,以相对公平的排名
,公式中的m相当于“先验概率”,每一次投票都是一个新的调整因子,使预估不断趋向于真实概率。因此,这种方法可以给一些投票人数较少的项目,以相对公平的排名
著名电影评分网站IMDB的排名算法采用了贝叶斯平均
公式: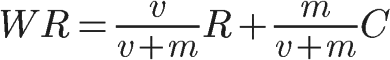
其中,
v是该电影的投票数量
m是top 250榜单需要的最少投票数(在阮一峰写文章的时候这个值是3000,现在,这个值已经是25000了)
R是该电影的投票平均分
C是全部电影的投票平均分
相当于IMDB为每个影片增加了25000张投票,并假设这25000张投票的得分为所有电影的投票平均分,使得投票数较少的电影也可以在贝叶斯推断的基础上与投票数较多的电影进行一个可信的比较
激励后进
作为以用户贡献内容为主的网站,我们必须把人的因素考虑进去,一定程度上,我们需要考虑对用户新发布的内容给予有力支持。前面所有例子中的时间的副反馈作用、抑制马太效应、冷门内容的处理等都包含了激励后进的因素在里面,下面是另外两种激励后进的方法
Youtube的订阅频道
Youtube是全球最大的视频网站,YouTube每个视频下面都有类似赞同和反对的投票,这与上面所有网站是类似的
Youtube的特点是每个视频作者有自己的频道,而用户可以订阅各种频道。很显然,用户订阅这个频道是因为喜欢和认同这个频道的内容,否则一般没人闲得慌去订阅自己看不惯的频道。这就是很明显的同质性趋势
当每个频道发了什么新视频时,Youtube会首先通知所有订阅者,这样几乎所有频道新发布的视频的前几十票到几千票(取决于频道的订阅数)基本都来自自己的订阅者,而且赞同/反对比往往都是50:1,100:1甚至500:1级别的,因为这时基本还只是小圈子内部的自娱自乐,当然没人投反对票
一旦某个视频开始火了,才会开始被Like到别的频道,被Youtube推荐到排行榜上,获得更广的受众,这时候该内容就已经完成了冷启动,获得了一定程度的赞同优势,而不会因为刚开始关注的人少,而湮没在无垠的信息海洋中
APP Store的分类榜单
如果只有一个排行榜的话,出于一些原因,还是有可能会有一些内容长期霸占排行榜前列,比如APP Store的免费应用榜单。类似于QQ、微信这样的老牌应用,质量上无懈可击,又是刚需,谁能拼得过他们呢,时间长了,可能整个榜单前50名都是基本不变的,榜单会失去意义
这时,往往并不是我们的算法出现了问题,因为我们的所有算法就是为了在公平、可信的前提下,将热门的、优秀的和新的内容带到用户面前。但我们仍然可以做些什么,比如一个APP Store中常用的做法包括:分类榜单、上升最快榜单、编辑精选榜单、收起已安装的应用等

其他因素
除了纯数学模型外,在以人为主的社区中,我们往往还可以借助其他信息来辅助确认一个帖子(内容)应有的价值(得分),其中比较常用的方法,就是权重系统
用户权重
之前看过一个节目叫做《最强大脑》,与很多节目一样,有一名选手在台上进行表演,然后有四名评委在台下进行打分。不同的是,这个节目的评委分为两种,包括三名嘉宾评委和一名科学评委,而得分的计算公式如下:
(Score嘉宾A+Score嘉宾B+Score嘉宾C) x Score科学评委
很显然,科学评委的评分至关重要,如果科学评委的分数很低,嘉宾的评分再高也是没什么用的
这就相当于为科学评委赋予了更高的权利,他的投票比其他人的投票更重要。同样在基于用户投票的排名算法中,我们往往也会为不同的用户赋予不同的权利,比如在UGC社区中,可能更加活跃的用户的投票更加真实(而不是刷票),或者关注人数更多的用户所产生的内容,质量高的可能性更大,再或者,在电商系统里,信誉度更高的商家所产生的内容就应该给予更好的排名
公式: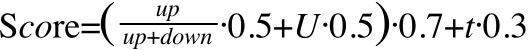
其中,
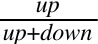 是帖子的好评率
是帖子的好评率
U是帖子作者的用户权重
t是时间因素
可以看到,帖子得分是一个与好评率、作者权重、时间相关的加权平均数,在评分系统中,将作者的因素考虑进去,相信更优秀的作者,更有机会产生好的内容,同时也有助于用户产生内容的激励措施
过滤欺骗
有人的地方就有江湖,对于一些“利益攸关”的榜单,我们还要考虑一些欺骗性的恶意刷榜行为,比如苹果的APP Store
关于过滤欺骗,上面的一些方法是有用的,包括:增加影响维度、用户权重(刷榜一般使用的僵尸用户很难获得很高的用户权重),在这方面,苹果的APP Store曾经做过的一些措施可供参考:
- 加长锁榜时间:
2012年初,苹果APP Store的排名算法有过一次大的变更:原本15分钟左右就会有所变化的榜单从下午三点开始进入“锁榜”情况,直到六点才恢复正常,并且这个锁榜的真空期不断加长,甚至到7小时以上
这段时间内的刷榜行为,无法马上见到效果,一些集中一段时间进行刷榜的快速冲榜行为受到了比较大的打击 - 榜单更新频率改为随机:
2015年初,苹果APP Store排行榜的更新时间由原来固定的三小时一次改为不定。App Store榜单排名更新时间不定对于用户的体验影响并不大,但是对于需要App Store上冲榜的公司而言却无形干扰了预判,进而增加了风险。
除了对更新频率的变化,APP Store也不断增加排行榜的影响维度,从只考虑下载量,到用户评价、内容质量、激活率等多方考量,越来越增大刷榜的困难程度。
一般来讲,普通UGC社区的榜单没有苹果榜单那么“利益攸关”,刷榜的问题也就不严重,而且榜单算法也更复杂(比如Stack overflow的算法),刷榜更难。我们所谓的欺骗过滤的含义也即是:由于刷榜困难所带来的付出要大于刷榜成功所带来的利益,而已
总结
上面的一切的一切,都是为了把用户感兴趣的内容带到用户的面前
我们假设用户感兴趣的内容是:热门的、冷门但不失优秀的和新产生的,以上的所有算法都是基于这一假设,如果这一假设有所变化,上面的算法也应有所变化(比如个性化推荐)
在将用户感兴趣的内容带到用户面前的过程中,我门追求的目标是:公平、可信、多维、抑制马太效应和鼓励后进
我们可以将所有算法及其作用整理为下表:
| 解决目标 | 解决方法 |
|---|---|
| 展现优秀内容 | 赞同票比例正反馈、投票趋势正反馈 |
| 展现热门内容 | 投票数数量、浏览数量、收藏数量、回答数量正反馈 |
| 展现新内容 | 时间副反馈(牛顿冷却定律) |
| 抑制马太效应 | 增加影响维度、对投票数使用对数算法、时间副反馈 |
| 可信与公平 | 威尔逊得分区间、贝叶斯平均 |
| 激励后进 | 时间副反馈、抑制马太效应、贝叶斯平均、个性化推送、分类榜单 |
| 过滤欺骗 | 用户权重、增加影响维度、随机更新榜单 |
参考
基于用户投票的排名算法,阮一峰
How Hacker News ranking algorithm works, Salihefendic
Hacker News算法讨论
Stack-overflow算法讨论
Reddit源代码
Reddit, Stumbleupon, Del.icio.us and Hacker News Algorithms Exposed!, Danny Dover
Reddit 评级算法的工作原理, Tiezhen WANG
Rank Hotness With Newton's Law of Cooling, EvenMiller
How Not To Sort By Average Rating, EvenMiller
马太效应,wiki
知乎的问题回答排序如何避免马太效应?
冷却定律,wiki
Binomial proportion confidence interval, wiki
区间估计—置信区间,张伟平
关于成功率信赖区间建构之探讨,王珊珊
Understanding Binomial Confidence Intervals, Philip Mayfield
置信区间,wiki
二项分布,wiki
贝叶斯概率,wiki
贝叶斯平均,wiki
贝叶斯推断及其互联网应用,阮一峰
如何策划一个流量分发类的产品,xidea
如何评价知乎的回答排序算法
苹果 App Store 免费 App 排名的标准是什么
Weighted arithmetic mean, wiki
The Dirichlet Distribution 狄利克雷分布,恒
APP Store排名因素、算法及变化
知乎如何计算用户在某个领域下的权重
排名算法主要涉及以下几个方面的内容:
1. 对赞同、反对和时间的处理
2. 抑制马太效应
3. 冷门内容的置信与公平
4. 激励后进
5. 权重系统和欺骗过滤